[テスト] 人工知能(無能?)カラオケ!! – 畳み込みニューラルネットワークによる動画の情景解析に基づく歌詞の自動生成
2016 BLOG
Recent Posts
そういえば… 年末にWIREDさんの忘年会にDJとして参加しました. 僕がいつものようにレコードを使ってDJしていたところ、レコードを裏返して針を落とした瞬間、かぶりつきで見ていた学生と思しき女性に驚かれました.「裏があるなんてすごいですね!」と声をかけてきたので、「カセットとかレーザーディスクとかにも裏があったでしょ. あれといっしょだよ」と返したところ、「レーザーディスクってなんですか??」 と真顔で聞かれました. そこか…..
閑話休題
少し前に告知しましたが、1月末にeAT金沢に参加してきました. 今日はその夜の余興での発表について書きます. 題して、
「昭和後期の民俗学的映像データ再活用をめぐって – 畳み込みニューラルネットワークによる情景分析とその応用」Nao Tokui, et al
小難しく書いてますが、要するに人工知能(ニューラルネットワーク)に昔のレーザーディスクカラオケのベタな映像の情景を分析させて、映像に写っているものから歌詞を(なんとなく)自動生成. 人間ががんばって歌う… という実験です. 当然生成される歌詞は毎回違います. メロディーは知っているとはいえ初見で見せられた歌詞を歌わないといけないという、なんとも歌い手泣かせな無茶振り企画. くどいですが、あくまで余興です! (でも、そちらがむしろそっちが本番?)
eATのイベント自体に誘ってくれた電通の菅野くん(@suganokaoru)と、夜の部でなにかやろっかという話になったときに、映像データを学習してなにかできたらいいよねという話をしていたところから始まりました。直接的に影響を受けたプロジェクトはこちらです. 先日ライゾマの機械学習ワークショップでも来日していたKyle McDonaldくんの実験.
NeuralTalk and Walk from Kyle McDonald on Vimeo.
ご存知の通り、Deep Learning特に畳み込みニューラルネットワーク(CNN)を使った画像解析技術の進歩には目覚しいものがあります. 特に昨年話題になったのは、CNNを使って画像を解析し何が写っているかを判別するだけでなく、さらにその情景を自然言語で記述する、という論文、システムです.
Deep Visual-Semantic Alignments for Generating Image Descriptions – Andrej Karpathy, Li Fei-Fei
http://cs.stanford.edu/people/karpathy/deepimagesent/

サンプルのコードがNeuralTalkとしてgithubで公開されてます.
NeuralTalk2 by Andrej Karpathy
https://github.com/karpathy/neuraltalk2
このNeuralTalkのモデルをラップトップコンピュータで動かしてWebカメラと繋ぐと、カメラで見ている町中の光景をニューラルネットワークでリアルタイムに記述するシステムができます.
それが上の動画です. また、Kyleくんの機械学習ワークショップでは ライゾマの登本さんが日本語のキャプションをつけるopenFrameworksのサンプルを公開されています.
精度の高さ(“ホットドックを食べる人”というキャプションが出た時の本人の驚き方が最高!) もさることながら、MacBook Proでリアルタイムに動くということも衝撃でした(あくまで学習済みのモデルを使う場合で学習自体には相当時間がかかります)。
また、どのような情景がCNNにとって認識しやすいのかというところに興味を惹かれました。学習時につかったサンプル写真に含まれている対象を認識しやすいのは、容易に想像がつきます. さらに、認識した光景から、コンピュータが勝手にストーリーを想像したらどうなるだろうか…
「ストーリー性と映像の関係がある程度ルースで、解釈の余地が残されている、それでいて人が見たときに共通理解としてのストーリーが簡単に見えてくるような映像ってなんだ??」…と考えてきたところで、冒頭のレーザーディスクの話とつながりました。そうだ、昔のコテコテ、ベタなカラオケの映像をコンピュータに見せてみよう!!
ということで作ったのが今回のシステムです.
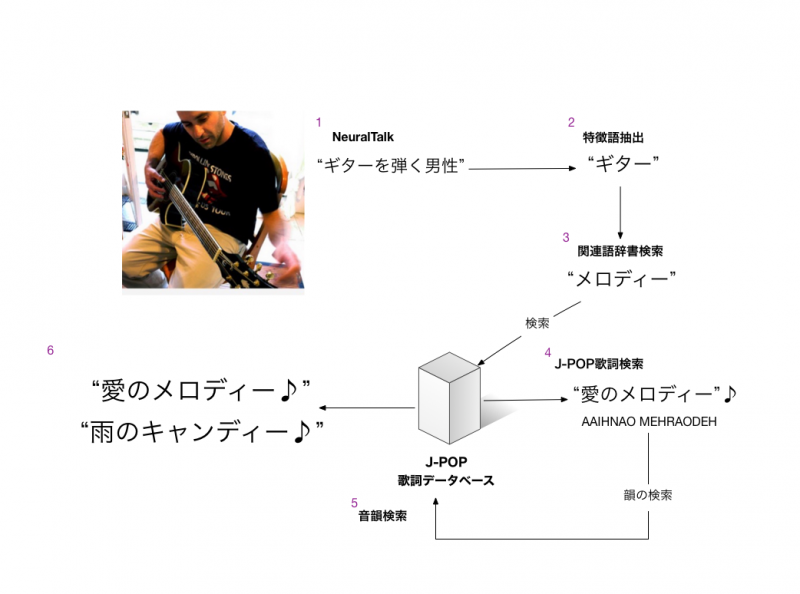
- NeuralTalkで映像にキャプションをつける -「ギターを弾く男性」
- キャプションの文章から特徴的な単語を抽出 -「ギター」
- 関連語/類義語をランダムに選ぶ(WordNet) – 「メロディー」「バンド」「音楽」など
- 3の単語を含む歌詞の断片をJ-POPの歌詞DBからランダムに選ぶ – 「愛のメロディー♫」
- 4のフレーズと音韻的に同じ長さで韻をふむ歌詞を同じデータベースから選ぶ – 「雨のキャンディー♪」
- 4と5のフレーズをつなげる -「愛のメロディー♫ 雨のキャンディー♪」
とまぁこんな流れです. 歌詞をつくる部分はまだまだ荒削りで、生成というよりは検索に近いですね. (RNNで歌詞のDBの文字列の並びを解析させて、文字列を生成するというのもやってみました。日本語っぽいフレーズが生成されることはされるのですが、日本語にはない単語を吐きだすことがあり、かなり歌いにくい、ということで今回は見送りました. 辞書をつかってフィルタをかけるなどの処理をすれば、RNNからの生成も使えるようになるかもしれません。)
文字数はなんとなくこのくらいかなという範囲で決めているだけで、音楽的な解析をやってるわけではありません. 映像の色のヒストグラムが大きく変化した=新しい場面に切り替わったと判断して、歌詞を生成するタイミングとしています.
そしていよいよ… 実際のカラオケの模様です. 左上に出ているのがNeuralTalkで生成した映像のキャプションです. これだけ荒っぽい実装でも、見ての通り、大盛り上がりでした! eATに来ている大人たちが遊び方をよく知ってる人たちだった…というのもありますが(eATの楽しさについてはまた記事を書きたいところです)、人間の適応力ってすごいですね。見たことがない歌詞でもそれなりに歌えてしまいます. Yesterdayの映像から歌詞を生成して日本語で歌うといったこともできました.
別の例. このときは左上に歌詞を表示しています. ところどころに絶妙な歌詞が生まれてます.
(泣き崩れる女性の絵に”泣いていい、泣いていたよ、巻き戻す、愛の中に”)
人間はカラオケのベタな映像をみたときに、なんてわかりやすい映像なんだろうと思います. この人間が思うコテコテ感、ベタ感. じつはかなりハイコンテクストでコンピュータにはぜんぜんわからない… AIがストーリーを理解するためには何が必要なのか、まだまだ先は長いですね.
(とはいえ、改めて昔のレーザーカラオケの映像を見返してみると、歌詞の内容とはまったく関係のないものが多いことにきづきました. バブルの名残の時代だったからでしょうか、制作チームが海外ロケに行きたかっただけなのではないかというものも少なくありません(笑)
先日のCNNによる白黒映像の自動着色は、ある種の想像力をコンピュータに与えることなのではないかと思っているのですが、今回のプロジェクトはもう一歩進めて、空想力を与える試みといってもいいかもしれません。適度な飛躍が起きる仕組みをどのように組み込んでいくかに面白みがありそうです。
AIの真面目な研究をやっている方には遊びのようにしかみえないかもしれませんが、意外とこういう遊びの中に、人工知能のような人間以外の新しい知性のかたちとの付き合い方のヒントが隠されているように思います. 今後もいろいろと遊んで行きたいと思ってます!
最後に… 発表の場を与えてくれた電通の菅野くん、こころよくカラオケに参加してくださったみなさま、ありがとうございました! 来年もまたバージョンアップしたカラオケとともに、eATでお会いしましょう!
CREDIT:
NeuralTalk2の実装: ml-notebook https://github.com/kylemcdonald/ml-examples
歌詞生成システム: 山田興生
関連リンク:
Generating Stories about Images – Recurrent neural network for generating stories about images
https://medium.com/@samim/generating-stories-about-images-d163ba41e4ed
[テスト] 畳み込みニューラルネットワークを用いたモノクロ動画の自動彩色
http://www.naotokui.net/2016/01/auto-color-cnn-jp/
Recent Posts
Featured Articles